Chapter 4: Fitting models (central tendency)
Quizzes are available to test your understanding of the key concepts covered in each chapter. Click on the quiz below to get started.
1. The fit of the model tells us about:
- The goodness of the sample to make observations of the real world
- The middle point in a distribution of scores
- The distance below and above the mean
- The accuracy with which we predict a phenomenon
The correct answer is D. We use models to summarize the general pattern of observed data. The fit of the model will tell us whether our model is good at predicting this pattern or not given the observed data.
2. What do the following symbols mean?
a) µ
b) n – 1
c) s2
d) 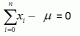
The correct answer is Short answers: a) population mean; b) degrees of freedom; c) variance; d) variance
3. What is it true about the interquartile range?
- Outliers have an effect on the result
- The mean is known as the second quartile
- It is the difference between the median score at the top and bottom 25% of scores
- It is the difference between the mean score at of the upper and lower quartile
The correct answer is C. the interquartile range divides the data into four equal parts (i.e., quartiles); the result is the median of the top and bottom quartiles, typically excluding the median score.
4. If we have an unbiased sample statistic, we conclude:
- That our data is not representative of the population
- That the sample statistic is a poor fit of the population parameter
- That the dispersion of our observed data is larger than that of the population
- That the expected value of the sample does not over or underestimate the population parameter
The correct answer is D. We use samples to estimate the population parameters such as the mean or variance. Our sample estimates are unbiased when their expected value corresponds to the value of the unknown population.
5. Given the following equation (y = (b0+b1 Xi)+errori) of a model, what does b0 mean?
- The average score
- The relationship between X and Y
- The value for an individual or object is given a score in the predictor variable
- The difference between observed data and a model of those data
The correct answer is A. With no other information about the relationship between predictors and the outcome, our best guess of the outcome is the mean, which is the simplest model we can fit.