Chapter 2: Descriptive Statistics: Tabular and Graphical Methods
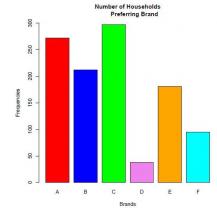
1. A survey of 1,095 households investigating attitudes toward 6 brands,A, B, C, D, E and F,in a certain product category reveals the following preference structure: of the 1,095 households , 272 express a preference for brand A; 212 prefer B; 297 prefer C; 38 prefer D; 181 prefer E; and 95 prefer F.
2. Use fd for all parts of exercise
Answer:
barplot(fd, col = c('red','blue', 'green', 'violet', 'orange', 'cyan'), ylim = c(0, 300), main = 'Number of Households Preferring Brand', xlab = 'Brands', ylab = 'Frequencies')
Answer:
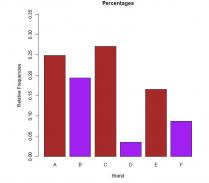
barplot(rf, col = c('brown', 'purple', 'brown', 'purple', 'brown', 'purple'), ylim = c(0, 0.35), main = 'Percentages', xlab = 'Brand', ylab = 'Relative Frequencies')
4. Use the Cars93 data set (included in the MASS package) to answer the next questions.
Answer:
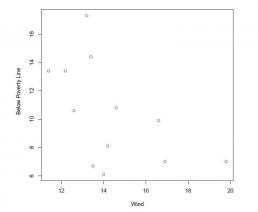
plot(poverty$Wind, poverty$Poverty,xlab = 'Wind', ylab = 'Percent Below Poverty Line', pch = 1, col = 'blue')