Chapter 2: Descriptive Statistics: Tabular and Graphical Methods
Answer:
#Comment1. Use the table() function to produce a frequency
#distribution and read the result into object named fd.
fd <- table(E2_1)
#Comment2. Use the barplot() function to provide a bar graph.
barplot(fd,
col = c('green', 'blue', 'red', 'yellow', 'purple','orange'),
ylim = c(0, 300),
main ='Number of Households Preferring Brand',
xlab ='Brands',
ylab = 'Brand Preference Frequencies' )
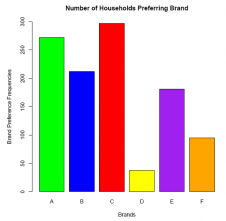
We have listed the arguments vertically (for the barplot() function), one per line, for the sake of minimizing clutter and improving visual clarity. In practice, however, there is no need to do so, and we can just as easily write the entire function (with its six arguments) on one line.
Answer:
#Comment1. Use the table() function to produce a frequency
#distribution and read the result into object named fd.
fd <- table(E2_1)
#Comment2. Create relative frequencies and assign to object rf.
rf <- fd / sum(fd)
#Comment3. Use the barplot() function to produce bar graph.
barplot(rf,
col = c('red', 'blue', 'red', 'blue', 'red', 'blue'),
ylim = c(0, 0.30),
xlab ='Brands',
ylab ='Relative Frequencies',
main = 'Proportion of Households Preferring Brand')
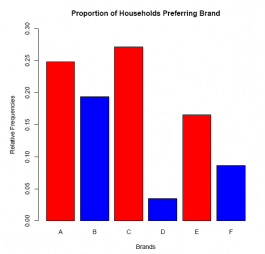
Answer:
#Comment1. Use the table() function to produce a frequency
#distribution and read the result into object named fd.
fd <- table(E2_1)
#Comment2. Create relative frequencies and assign to object rf.
rf <- fd / sum(fd)
#Comment3. Use the dotchart() function to create a dot plot.
dotchart(sort(rf),
xlab ='Relative Frequencies Brand is Preferred',
main ='Relative Frequencies by Brand',
pch = 20,
col ='blue')
## Warning in dotchart(sort(rf), xlab = "Relative Frequencies Brand is Preferred", : 'x' is neither a vector nor a matrix: using as.numeric(x)
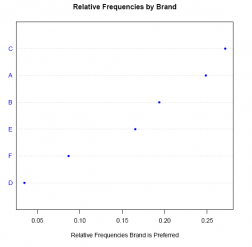
Note: it is necessary to sort the relative frequency data if we want the points in the dot plot to run in sequential order from the lower-left to the upper-right. This is done by nesting the sort() function as an argument in the dotchart() function. If we omit the sort() function, and include only the object name (in this case rf), the points in the plot are ordered alphabetically by default.
Note: This routine provides a warning message that we are free to ignore because the dotchart() function executes successfully and produces the dot plot image.
Answer:
#Comment. Use the hist() function to create a histogram
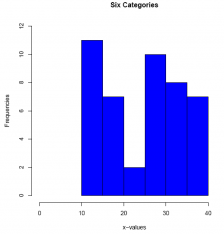
hist(E2_2,
breaks = c(9.99, 14.99, 19.99, 24.99, 29.99, 34.99, 39.99),
xlim = c(0, 45),
ylim = c(0, 12),
xlab = 'x-values',
ylab = 'Frequencies',
main =' Six Categories',
col = 'blue')
Answer:
#Comment. Use the hist() function to create a histogram.
hist(E2_3$var1,
breaks = c(0, 20, 40, 60, 80, 100),
col = 'purple',
ylim = c(0, 80),
xlab = 'x values',
ylab = 'Frequencies',
main = 'Five Categories')
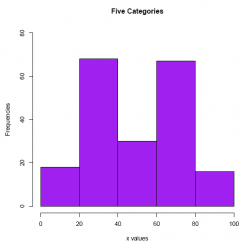
The histogram makes clear that even though the central tendency of the distribution is about 50 (according to the mean and the median), the data are indeed bimodal, not normal.
Answer:
#Comment. Use function hist() to create a histogram.
hist(E2_3$var1,
breaks = 10,
col = 'green',
ylim = c(0, 40),
xlab = ' x values',
ylab = 'Frequencies' ,
main = '10 Categories')
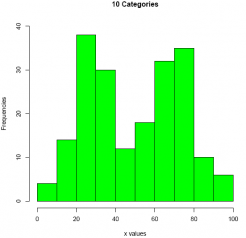
(Note that instead of defining the classes using breaks=c() as we did in the previous exercise, we can also use breaks=10. See the second argument of the hist ()function above.)
On closer inspection, it appears that using 10 categories rather than 5 offers no further resolution to the distribution of the data values. Even so, it is sometimes advantageous to break up the data into more (but narrower) categories because patterns that were not discernable with a smaller number of categories may be revealed when the data are spread out into more categories.
The next three exercises provide a bit of practice writing basic R code for the purpose of creating an image and interpreting its meaning. The three data sets are plot1, plot2, and plot3, and can be found on the companion website.
Answer:
#Comment1. Use the head(,3) function to identify the variable
#names and first 3 data records.
head(plot1, 3)
## x y
## 1 -3 4
## 2 -3 3
## 3 -2 3
#Comment2. Use the plot() function to create a scatter diagram
#of the two variables.
plot(plot1$x, plot1$y,
pch = 21,
col = "blue",
xlab = "x",
ylab = "y")
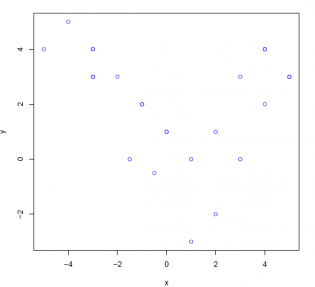
The scatter plot probably works best of all because it provides a picture of the association between two variables very clearly. In this case, the relationship between the two variables x and y is not linear but more parabolic.
Answer:
#Comment1. Use the head(,3) function to identify the variable
#names and first 3 data records.
head(plot2, 3)
## x y
## 1 -23 24
## 2 -33 50
## 3 1 9
#Comment2. Use the plot() function to create a scatter diagram
#of the two variables.
plot(plot2$x, plot2$y,
pch = 23,
col = "red",
xlab = "x",
ylab = "y")
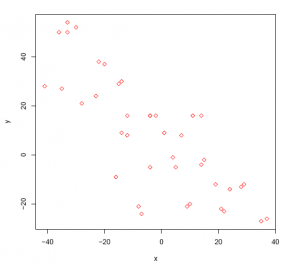
The two variables x and y appear to be negatively (and linearly) related.
Answer:
#Comment1. Use the head(,3) function to identify the variable
#names and first 3 data records.
head(plot3, 3)
## x y
## 1 -3 -4
## 2 15 9
## 3 23 21
#Comment2. Use the plot() function to create a scatter diagram
#of the two variables.
plot(plot3$x, plot3$y,
pch = 25,
col = "purple",
xlab = "x",
ylab = "y")
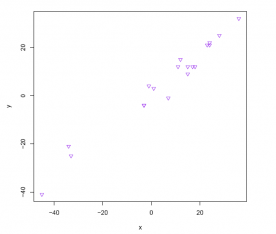
The variables x and y seem to be positively (and linearly) related.
The following exercises use the Cars93 data set that includes information on 93 makes and models of passenger vehicles on sale in the US in 1993. Since Cars93 must be downloaded from the MASS package, be sure to follow the directions provided at the beginning of the Chapter 2 end-of-chapter exercises in the book.
#Comment. Load the MASS package (contains the Cars93 data set).
library(MASS)
##
## Attaching package: 'MASS'
## The following object is masked from 'package:introstats':
##
## housing
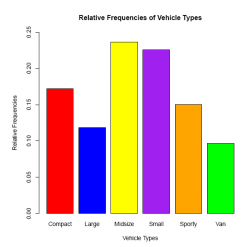
Answer:
#Comment. Use the barplot() function to provide the bar graph.
barplot(rfd,
col = c('red','blue','yellow','purple','orange','green'),
xlab ='Vehicle Types',
ylab ='Relative Frequencies',
main ='Relative Frequencies of Vehicle Types,
ylim = c(0, 0.25))
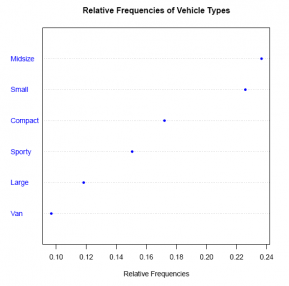
Answer:
#Comment. Use the dotchart() function to create a dot plot
dotchart(sort(rfd),
main ='Relative Frequencies of Vehicle Types',
xlab ='Relative Frequencies',
pch = 20,
col ='blue')
## Warning in dotchart(sort(rfd), main = "Relative Frequencies of Vehicle
Types", : 'x' is neither a vector nor a matrix: using as.numeric(x)
Answer:
#Comment. Use the hist() function with breaks=8.
hist(E2_4$Max.Price,
breaks = 8,
xlab ='Maximum Price of Passenger Vehicles (in $000)',
main ='Frequencies of Prices,
col = c('red','pink','blue,'yellow','purple','orange','grey','green'))
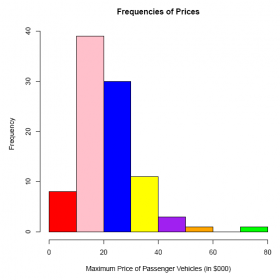
The frequency distribution as depicted by the histogram appears to be slightly skewed (from the normal distribution) to the right. Two outliers appear, one at $80, 000 (the Mercedes Benz 300E) and one at $50, 400 (the In niti Q45).
Answer:
#Comment. Use the plot() function with Max.Price on the horizontal
#axis, EngineSize on the vertical.
plot(E2_4$Max.Price, E2_4$EngineSize,
main ='A Scatter Diagram Relating Engine Size and Price',
pch = 23,
col ='orange',
ylab ='Engine Displacement in Liters',
xlab ='Vehicle Price')
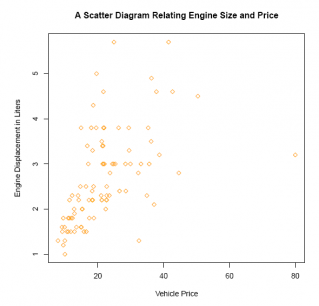
In general, there appears to be a positive relationship between engine size and price: engine size is (roughly) positively related to vehicle price.
Answer:
#Comment. Use the plot() function with EngineSize on the horizontal
#axis, Horsepower on the vertical.
plot(E2_4$EngineSize, E2_4$Horsepower,
main ='A Scatter Diagram Relating Engine Size and Horsepower',
xlab ='Engine Displacement in Liters',
ylab ='Maximum Horsepower',
pch = 19,
col ='blue')
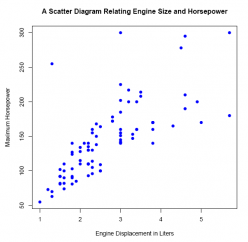
As expected, these two variables are positively and linearly related: in general, the larger the engine, the greater the horsepower.
Answer:
#Comment. Use plot() function with EngineSize on the horizontal
#axis, MPG.highway on the vertical.
plot(E2_4$EngineSize, E2_4$MPG.highway,
main ='A Scatter Diagram Relating Engine Size and Miles Per US Gallon',
xlab ='Engine Displacement in Liters',
ylab ='Highway Miles Per US Gallon',
pch = 24,
col ='red')
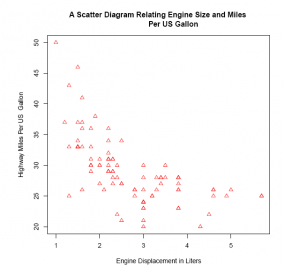
Unsurprisingly, the two variables are negatively (and somewhat linearly) related: in general, the larger the engine size, the lower the gasoline mileage.
Answer:
#Comment. Use the plot() function with Max.Price on the horizontal
#axis, RPM on the vertical.
plot(E2_4$Max.Price, E2_4$RPM,
main ='A Scatter Diagram Relating Vehicle Price and Revs per Minute',
ylab ='Revs per Minute at Maximum Horsepower',
xlab ='Vehicle Price',
pch = 20,
col ='purple')
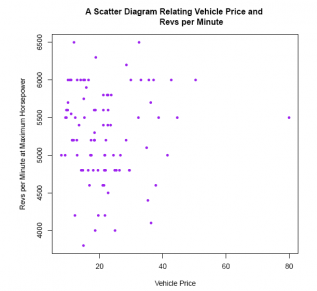
Since there is no reason to suspect that these two particular variables are related, either positively or negatively, we are not surprised to see this cloud of data points.