Chapter 1: Introduction and R Instructions
1. Using R, answer the following questions.
In later chapters, we introduce many additional R commands that are highly useful whenever we wish to perform computations.
2. Enter the following small data set directly into the R Workspace, and name it E1_1: 81, 17, 7, 55, 2, 98, 71, 47, 19, 8, 3, 10, 28, 65, 80. Check to make sure that E1_1 contains these elements, and answer the following questions.
#Comment1. Use the c() function to create object E1_1.
E1_1 <- c(81, 17, 7, 55, 2, 98, 71, 47, 19, 8, 3, 10, 28, 65, 80)
#Comment2. Examine contents of E1_1.
E1_1
## [1] 81 17 7 55 2 98 71 47 19 8 3 10 28 65 80
In the following chapters, we will learn many other R functions that help us perform basic data management and statistical analysis.
Answer: We can use the hist() function to create a histogram of the data.
#Comment. Use hist() function to provide histogram; set color blue.
hist(LakeHuron, col = 'blue')
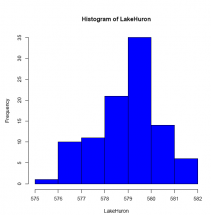
The histogram provides a bit more insight into how the data values are distributed. In fact, the data seem to be distributed normally (that is, somewhat bell-shaped) around the mean of 579 although pulled, or skewed, just slightly to the left.
Answer: We can use the rnorm(N) function to generate a set of N normally-distributed data values. (This is a function that we use again in later chapters.) Once we have generated the data and assigned them to an object, we use the hist() function to create a histogram.
#Comment1. Use function rnorm(10000) to generate 10,000
#normally-distributed data values; name the result E1_2.
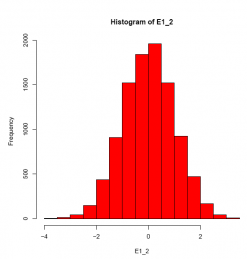
E1_2 <- rnorm(10000)
#Comment2. Use function hist() to provide histogram; set color red.
hist(E1_2, col = 'red')
9. Create a data frame consisting of the world's seven largest nations measured on three variables: population, GDP, and percent urban population. (Use Table 1.) Name the data frame E1_3; name the variables Nation, Population, GDP, and Percent Urban. Do not include the other variables.
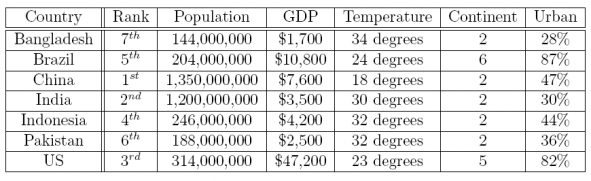
Table 1: Profiles of the World's Seven Most Populous Countries
10. Answer the following questions concerning the data frame E1_3.