Using Software in Qualitative Research
A Step-by-Step Guide
Chapter 13 – Interrogation (QDA Miner)
Chapter 13 in the book discusses interrogation of data that can happen at varied levels and at many moments during analysis. In Chapter 6 we refer to Text search tools where the content is explored and to Interrogation can also happen in terms of coding work you have previously achieved (see also Chapter 8 regarding retrieval of coded data). You might wish to discover relationships between codes which co-occur in some way in the data or need to compare them across subsets of data (indicated by the application of variables or attributes to data). Types of queries vary from simple to complicated tasks; summarized, charted information where the results are already available in the background is available in some software. See all coloured illustrations (from the book) of software tasks and functions, numbered in chapter order.
Sections included in the chapter:
Incremental and iterative nature of queries
Creating signposts for further queries
Identify patterns and relationships
Qualitative cross tabulations
Quality control, improving interpretive process
Tables and matrices
Charts and graphs
In QDA Miner, there are many ways to interrogate coding and content of the data. There are many types of query in QDA Miner such as the pattern matching Query by Example below (also discussed in Chapter 6). There are further advanced quantitative analyses of content at the push of a button when using the add-on the WordStat module
The TEXT RETRIEVAL function searches for specific text or combination of text in documents. You can search in all documents in a project or restrict the search to specific document variables. Searches can also be restricted to specific coded segments.
To start the text search feature, select the TEXT RETRIEVAL command from the RETRIEVAL menu. The following dialog box will appear.
On the first page, you can set the search conditions while results are displayed on the Search Hits page. When entering this dialog box, the second page is normally disabled. As soon as a search returns at least one hit, QDA Miner will enable this second page, allowing you to review the search hits and optionally assign codes to them.
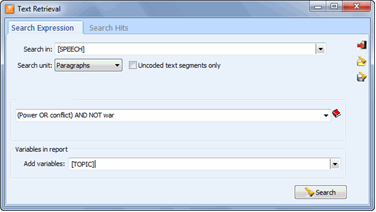
The SEARCH IN option allows you to specify which document variables to search. If the current project contains more than one document variable, you will have a choice of selecting either one or a combination of them. By default, all document variables are selected. To restrict the analysis to only a few of them, click the down arrow key at the right of the list box. You will be presented with a list of all available document variables. Select the variables on which you want the search to be performed.
The SEARCH UNIT option determines the search unit on which the search will be performed as well as what will be retrieved. You can select three different search units:
- If you select Documents as the search unit, QDA Miner will apply the search expression on each document associated with a specific case. If a specific document meets the search condition, its location will be returned
- When selecting Paragraphs as the search unit, QDA Miner will return any paragraph meeting the search condition
- Select Sentences to instruct QDA Miner to return sentences meeting the search condition
- Selecting Coded Segments as the search unit allows restricts the search to the text segments that have already been coded. When a coded segment meets the search condition, its entire text is returned, no matter whether it is a single word or several paragraphs. To restrict the search to specific codes, select the Selected radio button to the right side of this option and select the codes from the drop-down checklist by clicking the arrow button to the right end of this list. These codes can also be selected from a tree representation of the codebook by clicking the
 button. To perform the search on all codes, choose the All radio button
button. To perform the search on all codes, choose the All radio button
When searching sentences or paragraphs, one may restrict the retrieved text segments to those that have not been previously coded by enabling the Uncoded Text Segment Only check box.
SEARCH EXPRESSION This edit box is used to specify words or phrases being searched for. If disabled, the search will retrieve all text segments, no matter what their content. To search for a single word, simply enter the word in the edit box. In order to search for a phrase, you need to put the phrase between quotation marks or replace the space between words with underscore characters. For example, entering either:
example, entering either:
"quality of life"
or
quality_of_life
with retrieve text segments containing this phrase.
The Boolean operators AND, OR and NOT may also be used to build complex search expressions. For example, the following search string:
angry OR mad
will retrieve any search unit containing either the word "angry" or the word "mad". Parentheses may also be used to specify the evaluation order in complex search expressions. For example, if you enter the following search expression:
(angry OR mad) AND (son OR daughter OR child)
and set the Search Unit option to Paragraphs, QDA Miner will return all paragraphs containing either "angry" or "mad", but only if this paragraph also contains either one of the three words found in the second set of parentheses (e.g. "son", "daughter" or "child").
If several words are entered without a Boolean operator, then QDA Miner will assume that all those words are required, and thus behave as if you had entered an "AND" operator between those words.
Using wildcards in search expressions
A wildcard is a character or a set of characters that may be used in a search expression to represent one or more other characters. QDA Miner support the following wildcard:
|
? |
Matches any single character. For example F?T will find FAT, FIT and any other combination of three characters beginning with 'F' and ending with 'T' |
|
* |
Matches any number of contiguous characters. For example, T*ENT will return every word starting with 'T' and ending with 'ENT' such as TENT, TORRENT, TANGENT, etc |
|
# |
Matches any numeric character |
|
[ ] |
Matches any of the specified characters at that position. For example, [abc] will match if a or b or c at that position |
|
[^] or [!] |
Matches anything but the specified characters at that position. For example, [^abc] will match any single character, but a, b, or c |
|
[a – e] |
Matches a through e at that position |
|
_ |
The underscore character may be used to replace space within words. For example searching for QUALITY_OF_LIFE will match any instance of this phrase |
Performing thesaurus-based searches
A thesaurus-based search allows one to search for several words or phrases associated with a single thesaurus entry previously defined. For example, by entering a single category @GOOD (with an ampersand character "@" as a prefix), the program can automatically search for items that have been associated with this category, like "good", "fine", "excellent", "all right", "topnotch", etc. Names of categories may be typed directly in the search expression by preceding the category with a # character. For example, the following text search expression:
@GOOD and @SERVICE
will retrieve all text units containing either one of the words or phrases associated with the thesaurus entry GOOD along with any word or phrase included in the SERVICE thesaurus entry.
One may also insert a category, by clicking the ![]() button to display the thesaurus editing dialog box, selecting the thesaurus entry and then clicking the Insert button. The Thesaurus Editing dialog box allows one to create new entries or edit existing ones.
button to display the thesaurus editing dialog box, selecting the thesaurus entry and then clicking the Insert button. The Thesaurus Editing dialog box allows one to create new entries or edit existing ones.
WHOLE WORDS This option defines whether the words in the search expressions may be part of a word or if only whole words are to be found. For example, if this option is disabled, searching for a word like "bank" will return any search unit containing not only "bank", but also "banking", "bankruptcy", etc.
CASE SENSITIVE This option defines whether the search is case-sensitive or not. If enabled, only words with the exact same cases will be returned.
ADD VARIABLES This drop-down checklist box may optionally be used to add the values stored in one or more variables to the table of retrieved segments for the specific case from which a text segment originate.
To perform the search, click the ![]() button. The results of a search are displayed in a table located on the Search Hits page.
button. The results of a search are displayed in a table located on the Search Hits page.
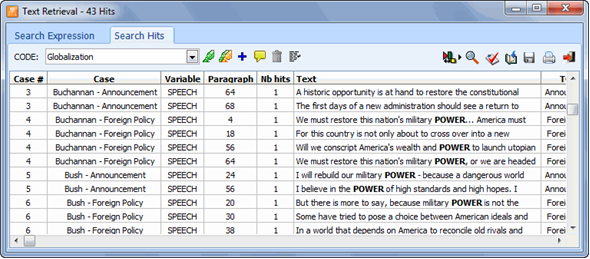
The table provides basic information on each hit, such as the case number and label, as well as the document variable in which it was found, the hit location, etc. To sort this list of hits in ascending order on any column values, simply click this column header. Clicking a second time on the same column header sorts the rows again in descending order.
Selecting an item in this table, either by clicking it or by using the keyboard cursor keys such as the UP or DOWN arrow keys, automatically displays the corresponding case and document in the main window. If the search unit was set to Paragraphs or Coded Segments, selecting a specific hit will also highlight the corresponding text segment. This feature provides a way to examine the retrieved segment in its surrounding context. You can also assign an existing code to the highlighted segment.
To assign a code to a specific search hit
- In the table of search hits, select the row corresponding to the text segment you want to code
- Use the CODE drop-down list located above this table to select the code you want to assign
- Click the
 button to assign the selected code to the highlighted text segment
button to assign the selected code to the highlighted text segment
To assign a code to all search hits
- Use the CODE drop-down list located above this table to select the code that you want to assign
- Click the
 button to assign the selected code to all text segments meeting the search expression
button to assign the selected code to all text segments meeting the search expression - Prior to the assignment of a code to all search hits, you may want to remove selected hits that do not correspond to what you were looking for. To remove a search hit from the list, select its row and then click the
 button
button
To export the table to disk
- Click the
 button. A Save File dialog box will appear
button. A Save File dialog box will appear - In the Save As Type list box, select the file format under which to save the table. The following formats are supported: ASCII file (*.TXT), Tab delimited file (*.TAB), Comma delimited file (*.CSV), MS Word (*.DOC), HTML file (*.HTM; *.HTML), XML files (*.XML), Excel spreadsheet file (*.XLS; *.XLSX), and SPSS data file (*.SAV)
- Type a valid file name with the proper file extension
- Click the SAVE button
To print the table
- Click the
 button
button
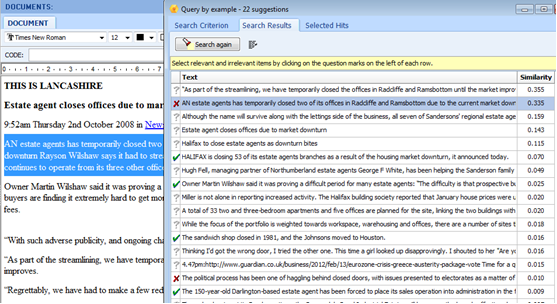
How to ‘Query by Example’ (pattern matching) (WordStat add-on software not required).
One of the advanced content analysis features which relies only on QDA Miner is the Query by Example tool.
This is illustrated below. It uses pattern matching to allow the user to select a key passage – sentence, paragraph or just phrase and by using the Query by Example tool discover similar passages in the rest of the data.
Select a short passage of data (as here…“estate agents temporarily closed two offices”)
from Retrieval menu – select Query by Example – see dialogue box below.
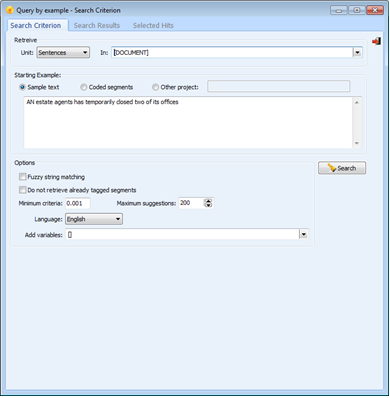
Along the top line (above) at the first drop-down usually you would choose the Sentence or Paragraph Unit of text to retrieve – and opt to search ‘In’ the ‘Document’ (type of data or variable – check the box alongside when you have selected the drop down)
You can experiment with other options in the dialogue box but you are now in a position to hit the Search icon in the dialogue box.
See below the list of ‘Suggestions’ which results… and in the vertical column to the left you can select the examples that fit – with one click or by a second click – reject them.
If you then Choose the ‘Selected Hits’ button you can add a code to the results if required